具備一致性的雜湊環 (Hash Ring)
- 本文為內行人才知道的系統設計面試指南一書之閱讀筆記 -
雜湊於分散式系統的應用
對於分散式系統來說水平擴展是一件非常重要的事情,而實現水平擴展當中的關鍵是能夠在多個伺服器之間能夠進行高效率、均勻的分配請求與資料,因此十分強調雜湊的一致性。首先回顧一般的雜湊做法,假設系統中有 個伺服器,那麼一個簡單的雜湊方法可以利用取餘數的方式來實作:
舉例來說,假設系統中有 4 部伺服器,那麼要儲存的快取資料便可以利用 來計算出其所應流向的伺服器,並且有如下的 key 值和其 value 對應的 hash value,後面計算出該 key 所儲存的伺服器編號:
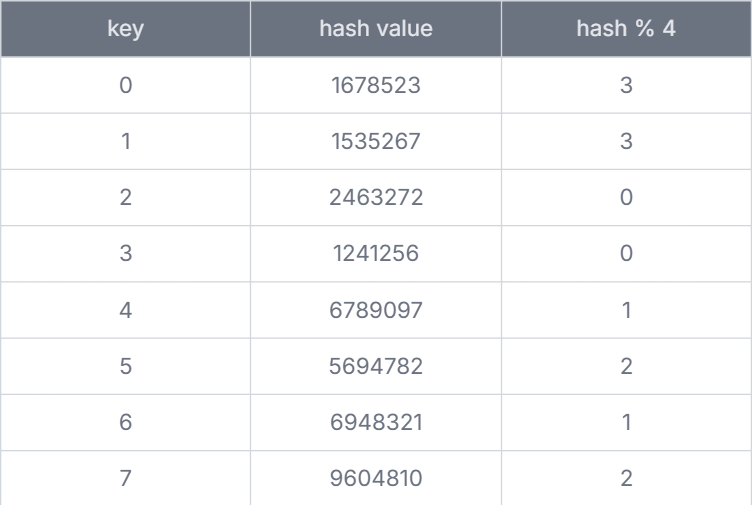
那麼在一開始的 key 對伺服器的分布應該會是像下面這樣:
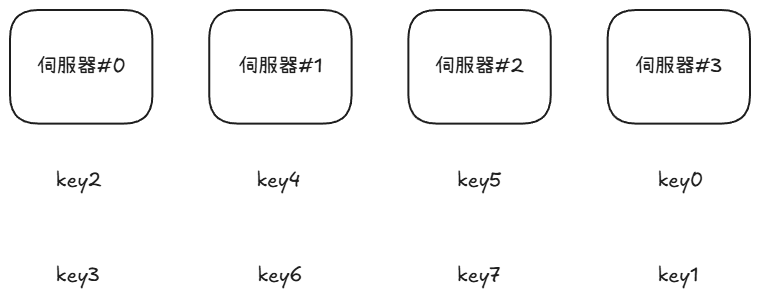
但今天因為遇到了一些技術問題導致 伺服器#1 突然故障了,這時候就必須要把原本儲存在 伺服器#1 的 key 值搬走,否則這些使用者就沒有辦法存取、使用服務了,由於現在只剩下 3 部伺服器的關係,所以只能把計算伺服器編號的方法改成 ,並且重新調整每個鍵值儲存的位置,更新過後的分布呈現如下:
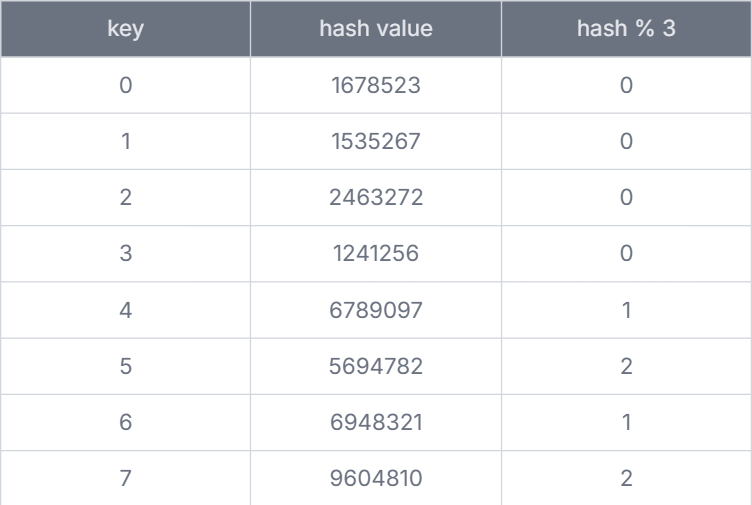
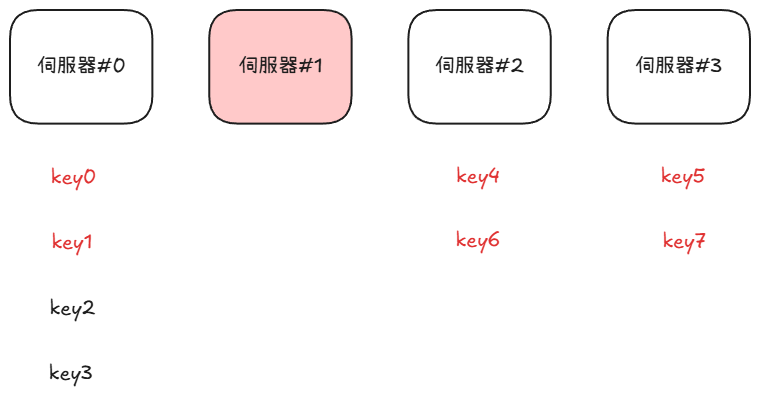
從這邊會發現到,除了原本壞掉的 伺服器#1 裡面的 key 被移走之外,由於計算雜湊的方法改變了,導致那些沒出事的伺服器裡面儲存的 key 也被迫要跟著重新洗牌找到新的對應伺服器,在短時間內如果沒有即時處理好資料移轉的工作就會引發大量的快取錯誤。
一致性的雜湊
因此為了要避免這種牽一髮動全身的狀況產生,勢必要使用一種較為安全的方法來處理雜湊的計算和對應,而一致性的雜湊定義為在雜湊表的大小改變時,平均只會有 個鍵需要重新調整對應關係,這邊的 代表 key 的數量,而 則代表 slot (插槽) 的數量 (此處對應的是伺服器的數量),而對於傳統的雜湊做法來說 (例如上述的取餘數),只要雜湊表大小一改變,幾乎所有的 key 值都需要調整對應關係,由此可見一致性雜湊對於效率的提升具有重大的影響。
雜湊環的設計
接下來便要介紹一致性的雜湊是如何運作的,首先我們可以先定義一個雜湊函式 它所輸出的值域是 ,想像這個值域是一條值域的空間 (hash space),計算出來的雜湊值會落在這條空間,那麼如果將首尾連在一起之後,便會形成一個雜湊環。
一開始的四部伺服器可以運用 也計算出它們所對應的雜湊值,在空間中就代表了它們分別落在雜湊環上的四個位置。同樣的,對於快取資料來說也可以在雜湊環上找到屬於它們的位置,至於哪個 key 要對應到哪部伺服器上,我們可以從 key 值出發,按照順時針的方向找到的第一部伺服器,就是該值所對應到的伺服器。
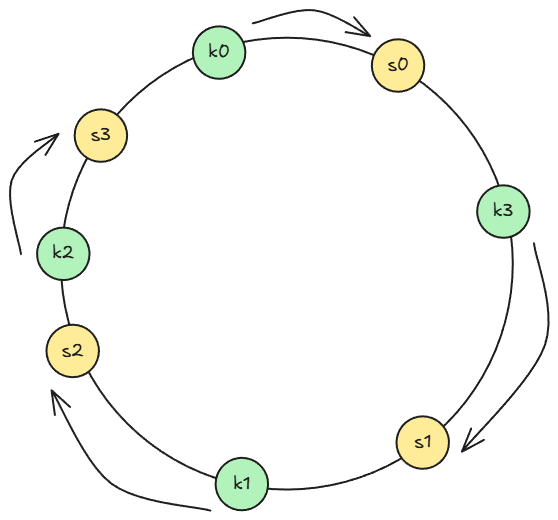
如果出現移除或新增伺服器的狀況時,調整的方式將會變得較為簡單,對於移除伺服器的狀況來說,就是將原本指到該伺服器的 key,繼續往同樣的方向尋找到下一部伺服器即完成調整,而新增伺服器的狀況的話,也是同樣只需要從新的伺服器逆時針往前就可以找到需要調整的鍵值,不會影響到其它伺服器與鍵值的對應關係。
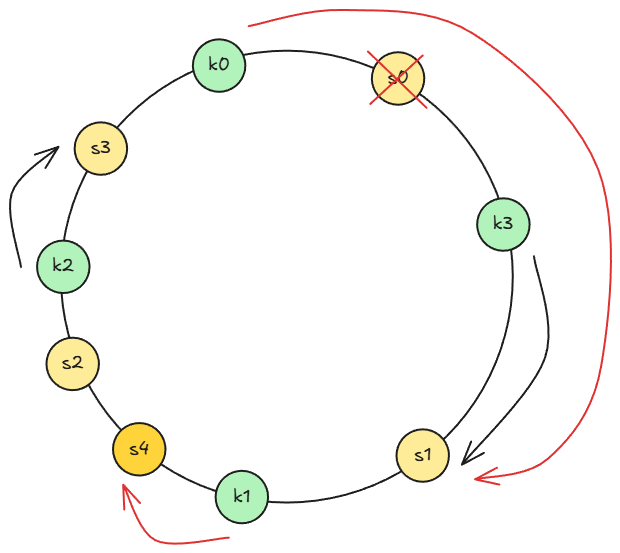
(移除了 伺服器#1,新增了 伺服器#4)
虛擬節點
以上的做法雖然可以讓鍵值對應的調整不會因為單一伺服器的變動而需要進行大幅度的變化,但還是會有幾個需要被處理的問題:
-
移除或添加伺服器會讓每個伺服器的分區差距產生變化
-
即使沒有移除或添加伺服器,無法保證一開始伺服器的分區大小接近
這邊的分區 (partition) 可以理解成每個伺服器的管轄範圍,也就是 key 值對應到該伺服器的範圍有多大,例如上圖經過移除和新增伺服器後,伺服器#1 的分區就明顯的比其他伺服器還要大得多,造成資料的分布出現不平均的問題。
這個時候我們會需要虛擬節點的概念來幫忙,也就是在雜湊環中讓多個節點指向一個伺服器,這麼一來每個伺服器在環上就會有好幾段分區,盡可能的把資料的分配給平均稀釋。像是以下面的圖為例,伺服器#0 和 伺服器#1 都各自有三個虛擬節點,而環上紅色的區域是代表 伺服器#0 的分區範圍,而藍色則是 伺服器#1 的範圍,藉此來達到平均負載分配的效果。理論上虛擬節點的數量越多,資料的分配也會更加平均,但相對的就需要花費更多空間來儲存這些虛擬節點,因此在設計的時候需要考量到這兩點來進行權衡。
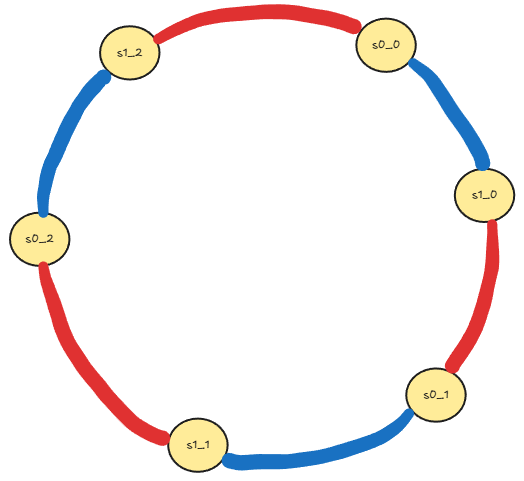
概念實作
以下是尚未加入虛擬節點的實作範例,單純將 node 使用 SHA-1 進行雜湊處理後記錄到 self.ring 中,其中較為關鍵的部分是 get_key_node 方法中使用了 python 裡 bisect 套件中的 bisect_right 方法,可以對一個排序好的陣列進行 binary search,當無法找到指定的數值索引的話則回傳最接近目標的右側的索引,套用到上面的理論當中正好是尋找一個 key 所對應的伺服器的做法。而當回傳的索引恰好等於 self.ring 的長度 (代表目標比陣列的所有數都還要大),則將其索引設為 0,將其分配給雜湊值最小的伺服器,形成一個雜湊環。
class HashRing: def __init__(self): self.ring = [] self.nodes = dict() def hash(self, key): return int(hashlib.sha1(key.encode()).hexdigest(), 16) def add_node(self, node): node_hash = self.hash(node) if node_hash not in self.ring: self.ring.append(node_hash) self.nodes[node_hash] = node self.ring.sort() def remove_node(self, node): node_hash = self.hash(node) if node_hash in self.ring: self.ring.remove(node_hash) del self.nodes[node_hash] def get_key_node(self, key): key_hash = self.hash(key) idx = bisect.bisect_right(self.ring, key_hash) if idx == len(self.ring): idx = 0 return self.nodes[self.ring[idx]]
後續使用 100 個 key 來進行分配,並且模擬了新增和移除節點的狀況,結果如下圖所示。可以觀察到在新增 node 4 前後的分布變化,主要是 node 3 的大部分 key 被轉移到 node 4 上面,至於 node 1 和 node 2 則沒有受到影響,至於移除 node 2 的結果則是讓其對應的 key 全部轉移到 node 4 身上,其餘的節點則沒有受到影響。
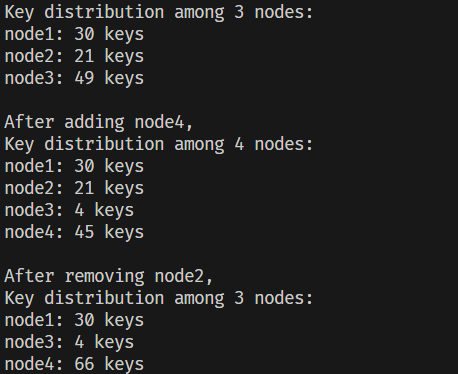
另外觀察到初始的 key 分布,由 node 3 包攬了大部分的 key 的儲存,因此可以透過加入虛擬節點的設計,盡可能的平均分攤每個節點的分區大小,具體的做法可以在初始化的時候另外帶入虛擬節點的數量,並在 add_node 和 remove_node 時一次加入。
class HashRing: def __init__(self, vnodes=50): self.vnodes = vnodes self.ring = [] self.nodes = dict() def hash(self, key): return int(hashlib.sha1(key.encode()).hexdigest(), 16) def add_node(self, node): for i in range(self.vnodes): node_hash = self.hash(f"{node}:{i:0>3}") if node_hash not in self.ring: self.ring.append(node_hash) self.nodes[node_hash] = node self.ring.sort() def remove_node(self, node): for i in range(self.vnodes): node_hash = self.hash(f"{node}:{i:0>3}") if node_hash in self.ring: self.ring.remove(node_hash) del self.nodes[node_hash] # get_key_node 不變 # ...
最後測試的結果如下圖,可以看到 key 的分布相較於加入虛擬節點之前有呈現更加平均的狀態。
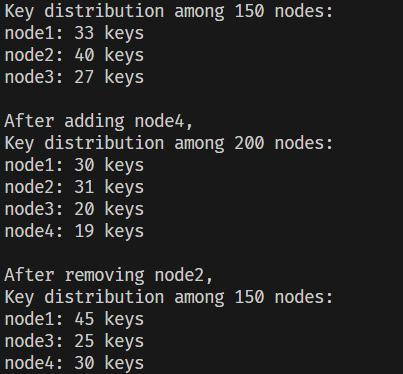
(這邊設定虛擬節點數量 = 50,因此圖中呈現的 node 數會是實際的 node 數量 * 50)